Method
diff history is a text sequence summarizing a neural language agent’s recent interactions in a decision-making setting, from "left" to "right." A visualization is provided below.
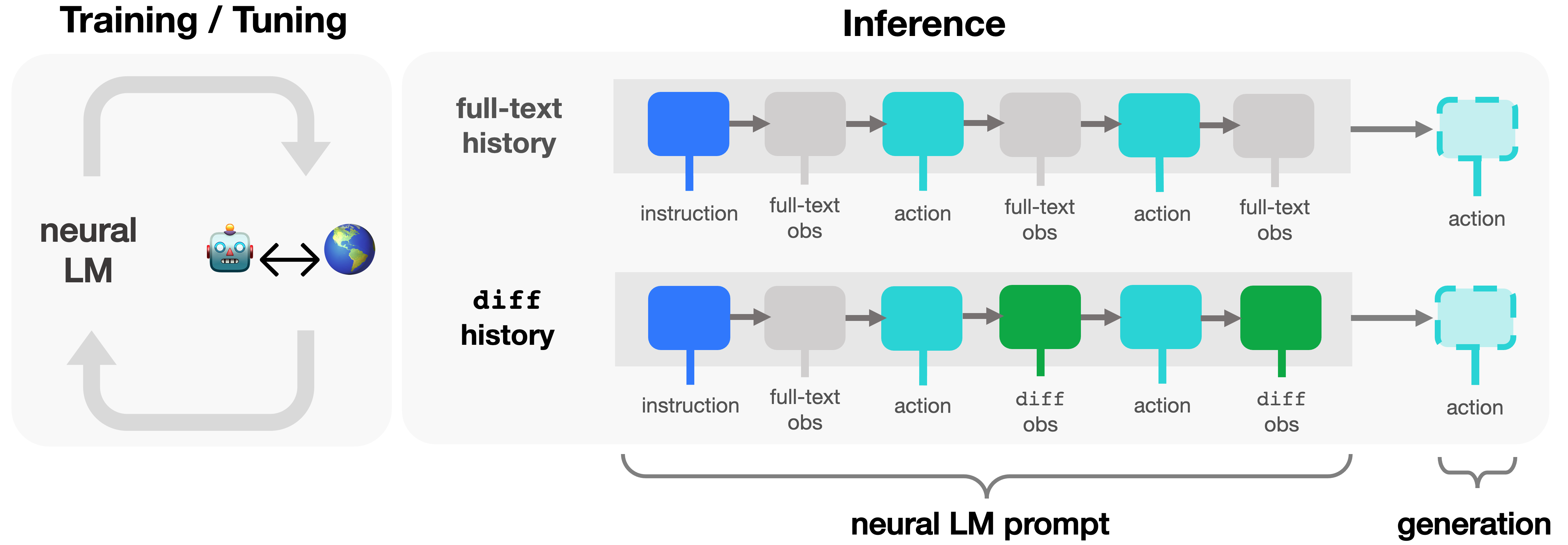
As shown above, diff histories consist of several components: (1) an instruction describing the task; (2) an “anchor” full-text observation; and (3) the subsequent actions taken by the agent as well as the observed, resultant text deltas in the world state. At inference-time, we can flexibly resize the history horizon provided to LM agents, up to the model context-length.
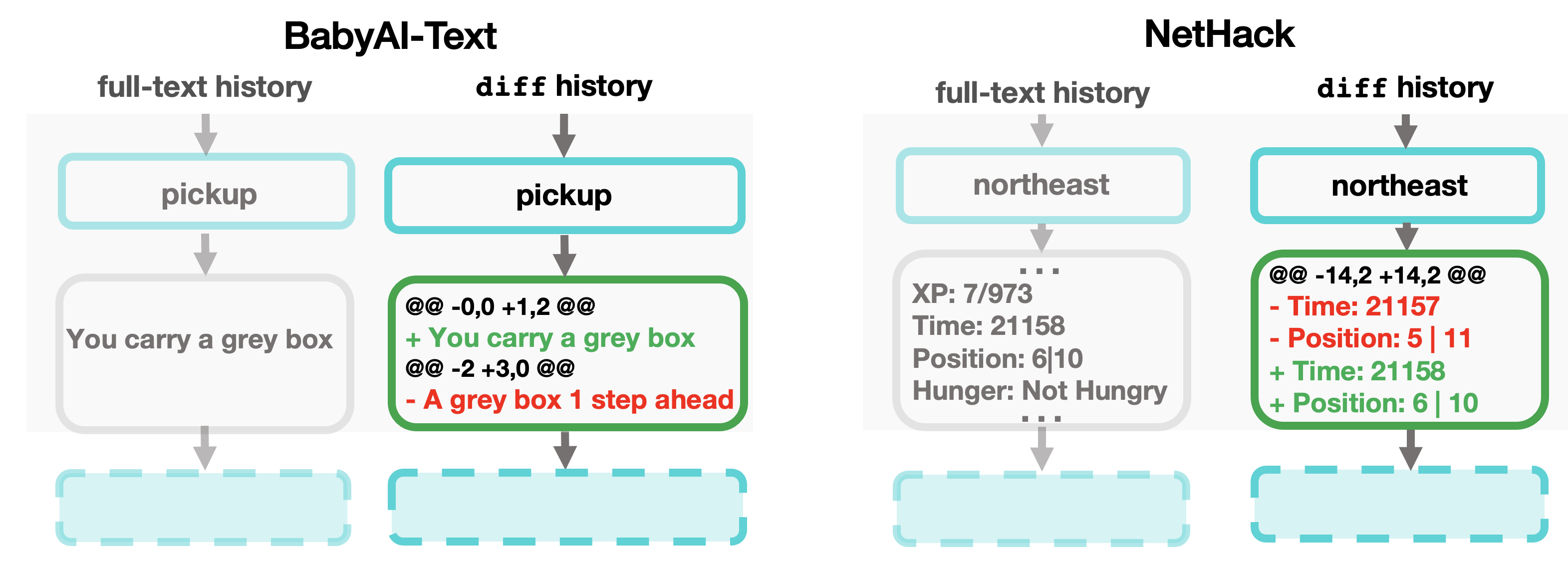
Why diff history? Text deltas returned by diff have a rich but simple algebraic structure (see the examples above). In text-based decision-making settings with natural language observations, the matching algorithm underlying the diff operator can also localize the high-level changes in environment properties, attributes, and object states that occur between consecutive timesteps of interaction. Thus, diff history provides a dense learning signal for instruction tuning LMs on action prediction. In high-dimensional environments with complex and verbose per-timestep observations, diff history can also act as a soft-compression mechanism, preserving information while reducing token counts to yield agents with longer memory horizons at fixed context-length.
Results
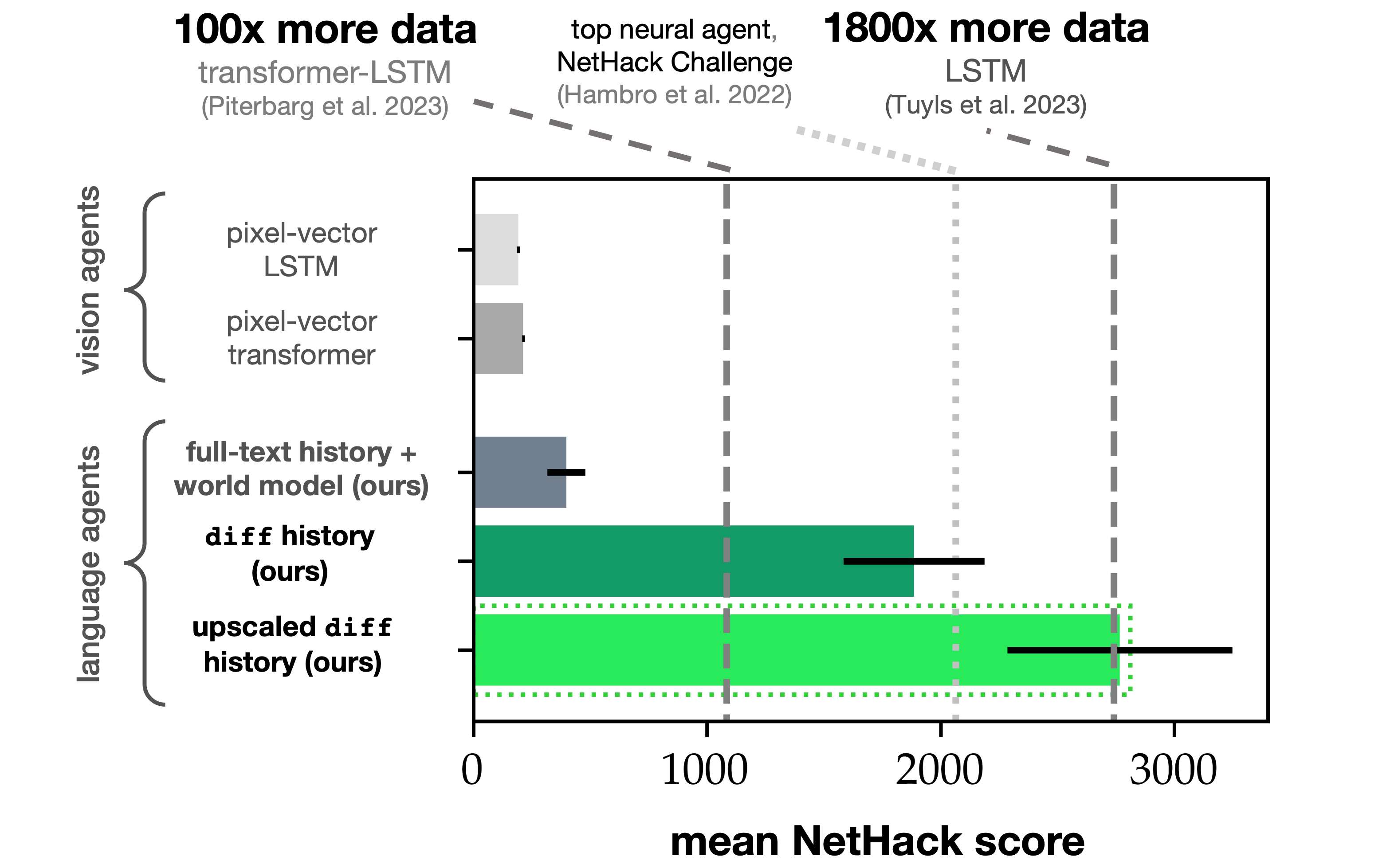
In NetHack, LMs with diff history match previous state of the art performance for data-driven agents despite tuning on 1800x fewer labeled demonstration data.
Ablating diff observations from interaction histories in favor of full-text observations results in a 98% decline in mean LM agent score on withheld seeds of the game, suggesting that diff is responsible for the performance gains that we observe.
Introducing an auxiliary "world model" prediction objective somewhat reduces the gap between diff and full-text interaction history agents. LMs with diff history also outperform vision-language baselines trained on the same demonstration data by 780% in mean test-time score.
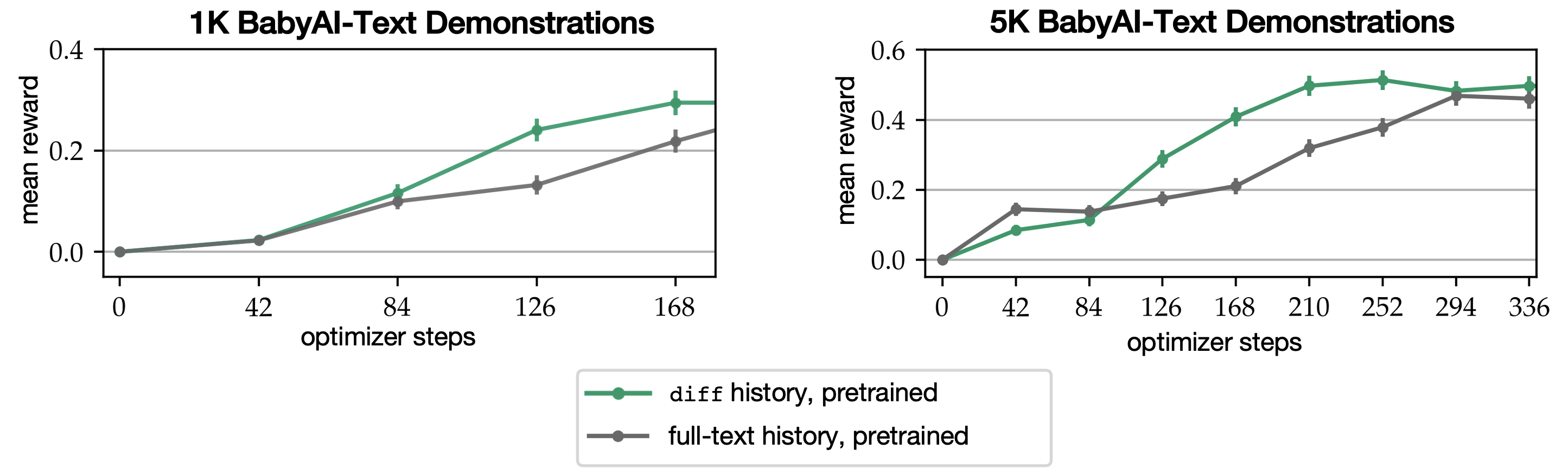
diff history improves the quality of inference-time LM generations resulting from low-resource instruction tuning, reducing FLOPs-to-convergence by 25% in both low-data and ultra low-data tuning settings.
BibTeX
@misc{piterbarg2023diff,
title={diff History for Neural Language Agents},
author={Ulyana Piterbarg and Lerrel Pinto and Rob Fergus},
year={2023},
eprint={2312.07540},
archivePrefix={arXiv},
primaryClass={cs.AI}
}